
New more efficient AI Architectures required
In recent years, natural language processing (NLP) and large language models (LLMs) have been revolutionized by transformer models. These refer to a type of neural network architecture that excels at tasks involving sequences. The transformer learns contextual meaning by analysing relationships in sequential data, such as the words in a sentence. It is a deep learning architecture created by Google, based on the multi-head attention mechanism. One advantage of transformers is that they do not have recurrent units, resulting in shorter training times than earlier recurrent neural architectures like long short-term memory (LSTM). This architecture is widely used in natural language processing, computer vision, audio processing, multi-modal processing, and robotics. Additionally, it has led to the development of pre-trained systems such as generative pre-trained transformers (GPTs) and BERT.
An Imagination of a Transformer Architecture as King of AI by Nathan Paull.
"The Sora video-generating model by OpenAI and text-generating models like Claude by Anthropic, Gemini by Google, and GPT-4o all rely on transformers as their foundation. However, transformers are inefficient at processing and analysing large amounts of data when running on standard hardware. This inefficiency is causing significant and potentially unsustainable increases in power demand as companies develop and expand infrastructure to meet the requirements of transformers."
Hence, researchers are actively exploring new architectures that could replace or augment transformers. This has been widely documented, including in Nathan Paull’s article in the AI Atlas: Beyond the Transformer: The Elements of Future AI Architectures. He outlines several promising candidates:
Retentive Networks, or RetNet, are designed to handle long sequences more efficiently than transformers using linear rather than quadratic scaling. This approach reduces computational complexity and memory requirements, making RetNet a strong contender for tasks involving long-range dependencies.

Initially introduced by Stanford researchers, Mamba is a new sub-quadratic transformer alternative with improved efficiency and scalability. It is based on state space models (SSMs) to maintain long-range dependencies and handle parallel training. The selective attention mechanism of Mamba enables it to process large datasets and long sequences without performance degradation. Mistral recently introduced Codestral Mamba as an alternative to transformers, offering improved computational efficiency and the ability to handle larger datasets. Mamba's architecture reduces computational complexity, enabling faster processing times and lower resource consumption, making it an attractive option for industries seeking sophisticated AI integration with lower computational demands.
"RWKV (Recurrent Weighted Key-Value) is a variant of the linear transformer specifically designed to reduce computational complexity while maintaining high performance. It combines the strengths of RNNs and transformers, providing excellent performance, fast inference, and quick training. RWKV operates without attention mechanisms and can be trained similarly to a GPT transformer. This makes it a potential "transformer killer" due to its efficiency in handling long sequences."

Hyena targets transformers' limitations by emphasizing efficient sequence modelling. It utilizes a mix of long convolutions and gating to handle sequences with millions of tokens, substantially extending the context length in sequence models. Hyena achieves performance on par with transformers on tasks like ImageNet, indicating its potential beyond language modelling.
The new architecture called test-time training (TTT) was developed by researchers at Stanford, UC San Diego, UC Berkeley, and Meta over a year and a half. According to the research team, TTT models can process more data than transformers while using less compute power. In simple terms, the internal machine learning model of a TTT model, unlike a transformer’s lookup table, doesn't increase in size as it processes more data. Instead, it encodes the processed data into representative variables called weights, making TTT models highly effective. The size of the TTT model's internal model remains unchanged regardless of how much data it processes.
Matrix multiplications (MatMul) are the most computationally expensive operations in large language models (LLM) using the Transformer architecture. As LLMs scale to larger sizes, the cost of MatMul grows significantly, increasing memory usage and latency during training and inference.
Researchers at the University of California, Santa Cruz, Soochow University, and the University of California, Davis have developed a new architecture that eliminates matrix multiplications from language models while maintaining strong performance at large scales. This breakthrough simplifies operations and reduces the need for large GPU clusters during training and inference phases, resulting in significant savings in memory and computation.
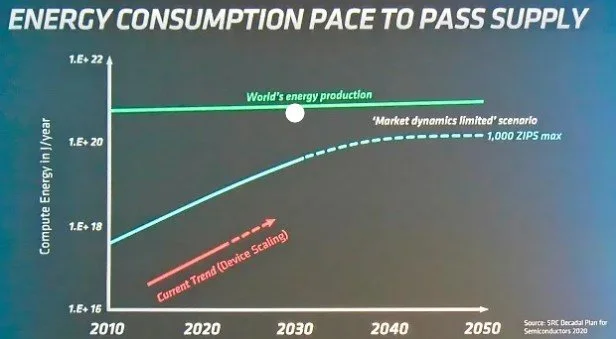
Future AI architectures must also be scalable and compatible with existing hardware to ensure widespread adoption. Key considerations include hardware compatibility, efficient resource utilization, and scalability. It is important to develop techniques that allow models to run efficiently on various hardware platforms and make the best use of available computational resources. Additionally, models should be able to handle increasing amounts of data and complexity without significant performance degradation.
While transformers have set a high standard in AI, the search for potential replacements is driven by the need for more efficient, scalable, and versatile models. Emerging architectures such as RetNet, Mamba, RWKV, and Hyena show promise in addressing the limitations of transformers. Hybrid approaches and enhancements, such as integrating symbolic reasoning and developing efficient transformer variants, further contribute to the evolution of AI.